Electricity Grid Drift Detection (Australia)
This example works on the Australian electricity grid dataset. The goal is to predict the class label of the grid status (binary classification) while handling concept drift in streaming data.
Models
We use the following models and components:
- HoeffdingTreeClassifier as the base classifier, suitable for streaming data.
- DDM (Drift Detection Method) to detect concept drift in the data stream.
- DriftRetrainingClassifier as a meta-algorithm that wraps the base classifier and retrains it when drift is detected by DDM.
We also use the following metric for evaluation:
- Accuracy
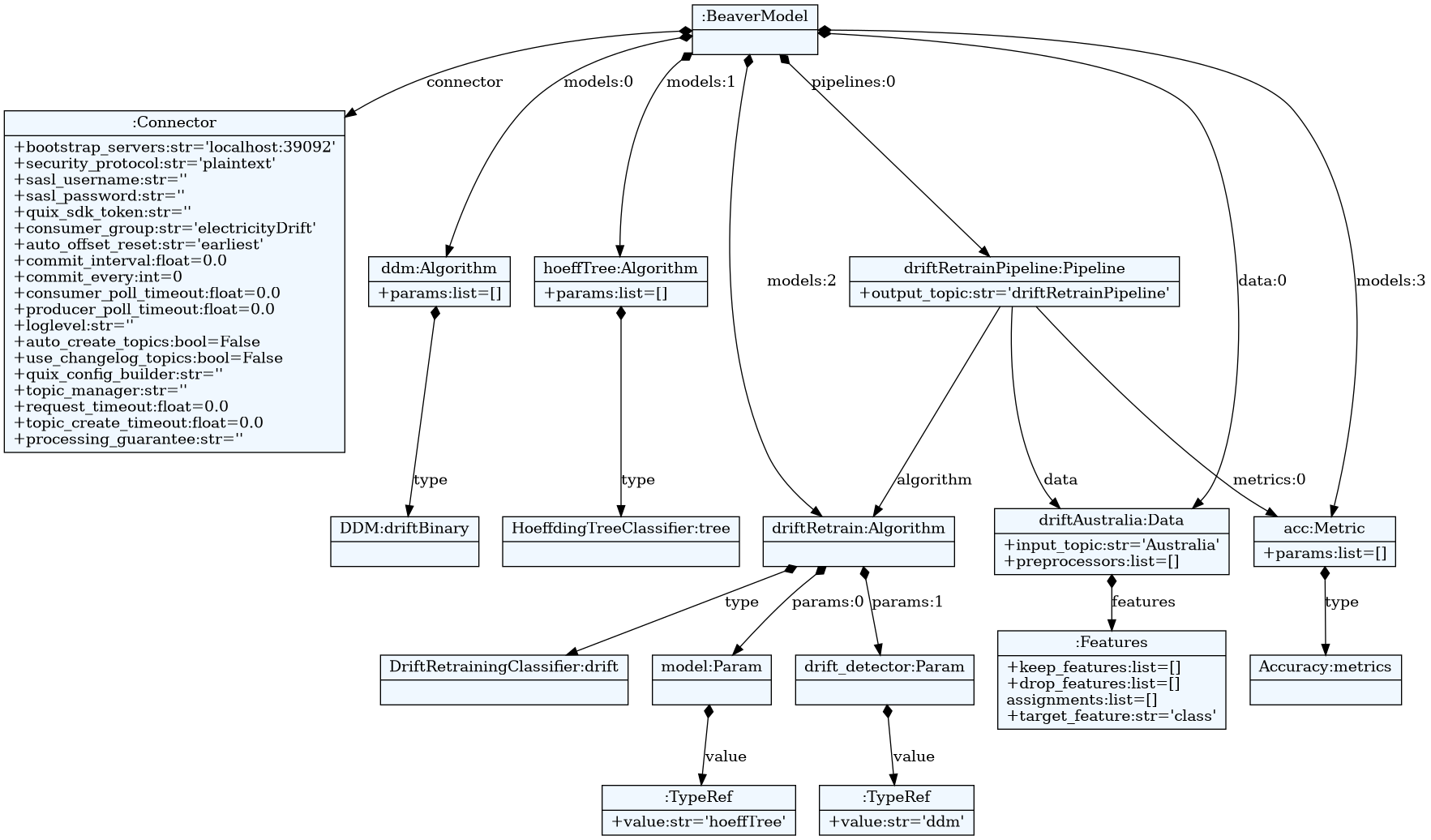
Beaver File Structure
Let's see how we would write the beaver file:
Connector
We start by defining the connector, specifying the Kafka bootstrap servers and security protocol.
connector {
bootstrap_servers = "localhost:39092"
security_protocol = "plaintext"
consumer_group = 'electricityDrift'
auto_offset_reset = "earliest"
}
Models
We define the drift detector, base classifier, and the meta-classifier:
algorithm <DDM> ddm
algorithm <HoeffdingTreeClassifier> hoeffTree
algorithm <DriftRetrainingClassifier > driftRetrain
params:
model=hoeffTree,
drift_detector=ddm
Metric
We define the evaluation metric:
metric <Accuracy> acc
Data
We define the data source and specify the target feature:
data driftAustralia {
input_topic = "Australia"
features:
target_feature = class
}
Pipeline
Finally, we define the pipeline that brings everything together:
pipeline driftRetrainPipeline {
output_topic = 'driftRetrainPipeline'
data = driftAustralia
algorithm = driftRetrain
metrics = acc
}
And that's it! This setup allows you to monitor and adapt to changes (concept drift) in the Australian electricity grid data stream, ensuring the classifier remains accurate over time by automatically retraining when drift is detected.
connector {
bootstrap_servers = "localhost:39092"
security_protocol = "plaintext"
consumer_group = 'electricityDrift'
auto_offset_reset = "earliest"
}
algorithm <DDM> ddm
algorithm <HoeffdingTreeClassifier> hoeffTree
algorithm <DriftRetrainingClassifier > driftRetrain
params:
model=hoeffTree,
drift_detector=ddm
metric <Accuracy> acc
data driftAustralia {
input_topic = "Australia"
features:
target_feature = class
}
pipeline driftRetrainPipeline {
output_topic = 'driftRetrainPipeline'
data = driftAustralia
algorithm = driftRetrain
metrics = acc
}
Figure of the beaver model can be seen below: