Heart Failure
This example works on the Heart Failure Dataset. There are 11 clinical features for predicting heart disease events. We will use classification methods to try and correctly predict if there is an underlying heart disease or not (binary classification). We will use 3 models:
- KNNClassifier
- AMFClassifier and
- LogisticRegression
We will also preprocess the data. In particular we will use
- StandardScaler for
numbertype features and - OneHotEncoder for
strtype features
Finally, to evaluate the models we will use 3 metrics:
- Accuracy
- Recall
- ROCAUC
Let's see how we would write the beaver file:
Connector
We start with the connector. We need to define the bootstrap_servers (where do we connect) and the security_protocol (plaintext/ssl) variables. All the others are optional
connector {
bootstrap_servers = "localhost:39092"
security_protocol = "plaintext"
consumer_group = 'heart-failure'
auto_offset_reset = "earliest"
}
Models
The models can be defined in whatever order you want. The only prerequisite is that if a model is used as a parameter on another model, you need to define this model first.
So in our case we have 3 algorithms (KNNClassifier, AMFClassifier, LogisticRegression), 1 optimizer (SGD), 2 composers of type SelectType for picking the numbers and str separately. Note: If you want to select a certain type of values and process them but you also want to maintain the other types you need to explicitly also select the others and just pass them through, otherwise River will throw an error. If you don't want the other types, its better to keep only the features you want with said type otherwise River expects a preprocessor type for these features too.
Then we have our 2 preprocessors (OneHotEncoder, StandardScaler) and finally our 3 metrics (Accuracy, Recall ROCAUC). The models can be defined as such:
algorithm <KNNClassifier> knn
algorithm <AMFClassifier> amf
params:
n_estimators=10,
use_aggregation=True,
dirichlet=0.5,
seed=1
optimizer <SGD> sgd
params:
lr = 0.1
algorithm <LogisticRegression> logistic
params:
optimizer = sgd
composer <SelectType> select
params:
(int , float)
composer <SelectType> selectstr
params:
str
metric <Accuracy> accuracy
metric <Recall> recall
metric <ROCAUC> roc
preprocessor <OneHotEncoder> encoder
preprocessor <StandardScaler> scaler
As you can see there is no order apart from the optimizer being initialized before the logistic regressor model that is using it.
After that we need to define the data that will use. We will define the input source, the features that we want (in our case we will define our target feature) and the preprocessors that are going to be used. To define a pipeline of preprocessors we use the | symbol while to imply that they will be used on different data we use the + symbol
data Heart_Failure_Prediction {
input_topic = "Heart_Failure_Prediction"
features:
target_feature = HeartDisease
preprocessors = select | scaler + selectstr | encoder
}
Finally we define our pipelines. We need to define
- The output source (optional)
- The data we will use (in our case Heart_Failure_Prediction)
- The algorithm of the pipeline
- The metrics that we will use for evaluating the model
Our 3 pipelines are:
pipeline KNNClassifierPipeline {
output_topic = 'KNNClassifierPipeline'
data = Heart_Failure_Prediction
algorithm = knn
metrics = accuracy , recall , roc
}
pipeline amfClassifierPipeline {
output_topic = 'amfClassifierPipeline'
data = Heart_Failure_Prediction
algorithm = amf
metrics = accuracy , recall , roc
}
pipeline logisticPipeline {
output_topic = 'logisticPipeline'
data = Heart_Failure_Prediction
algorithm = logistic
metrics = accuracy , recall , roc
}
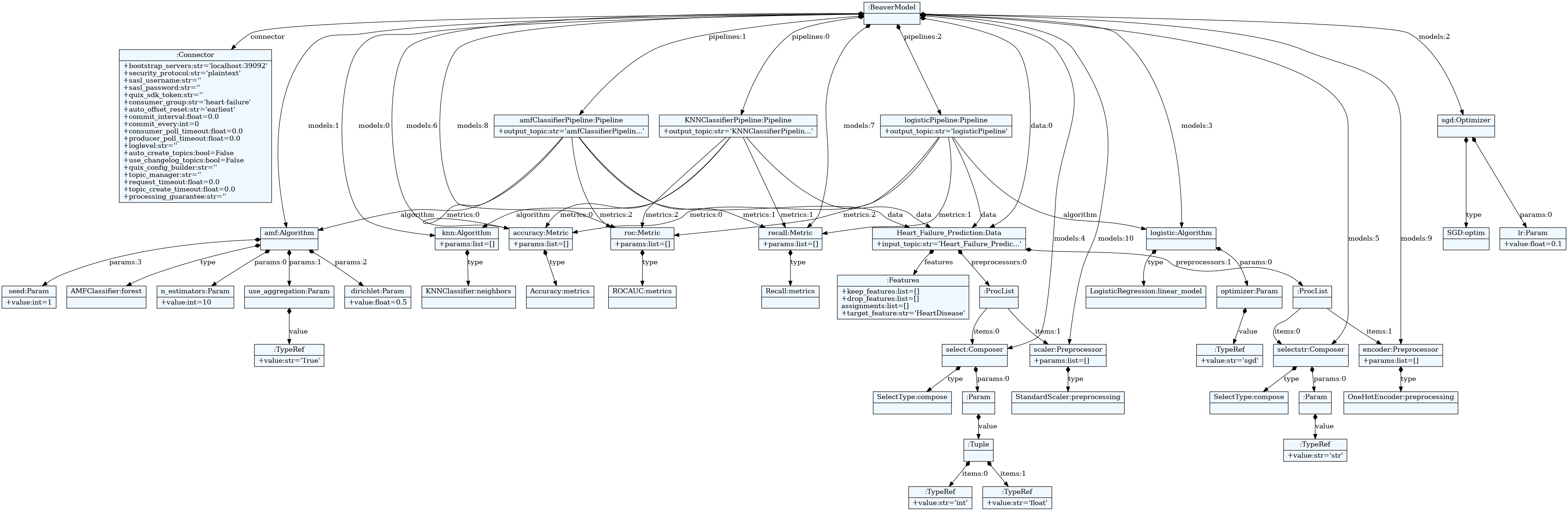
And that's it! Now the final Beaver file is :
connector {
bootstrap_servers = "localhost:39092"
security_protocol = "plaintext"
consumer_group = 'heart-failure'
auto_offset_reset = "earliest"
}
algorithm <KNNClassifier> knn
algorithm <AMFClassifier> amf
params:
n_estimators=10,
use_aggregation=True,
dirichlet=0.5,
seed=1
optimizer <SGD> sgd
params:
lr = 0.1
algorithm <LogisticRegression> logistic
params:
optimizer = sgd
composer <SelectType> select
params:
(int , float)
composer <SelectType> selectstr
params:
str
metric <Accuracy> accuracy
metric <Recall> recall
metric <ROCAUC> roc
preprocessor <OneHotEncoder> encoder
preprocessor <StandardScaler> scaler
data Heart_Failure_Prediction {
input_topic = "Heart_Failure_Prediction"
features:
target_feature = HeartDisease
preprocessors = select | scaler + selectstr | encoder
}
pipeline KNNClassifierPipeline {
output_topic = 'KNNClassifierPipeline'
data = Heart_Failure_Prediction
algorithm = knn
metrics = accuracy , recall , roc
}
pipeline amfClassifierPipeline {
output_topic = 'amfClassifierPipeline'
data = Heart_Failure_Prediction
algorithm = amf
metrics = accuracy , recall , roc
}
pipeline logisticPipeline {
output_topic = 'logisticPipeline'
data = Heart_Failure_Prediction
algorithm = logistic
metrics = accuracy , recall , roc
}
The beaver model figure can be seen below: