World Happiness Report
This example demonstrates how to build and evaluate multiple regression pipelines using the World Happiness Report dataset. The goal is to predict the happiness score of a country based on various features.
Data Source
- Input Topic:
World_Happiness_Report - Target Feature:
score(the happiness score to predict) - Dropped Feature:
overall_rank(not used for prediction)
Preprocessing
- Feature Selection: Numeric (
int,float) and string (str) features are selected separately. - Scaling: Numeric features are standardized using
StandardScaler. - Encoding: String features are one-hot encoded with
OneHotEncoder.
Algorithms
Three regression algorithms are used:
- LinearRegression: A simple linear model with a specified learning rate for the intercept.
- HoeffdingAdaptiveTreeRegressor: An adaptive tree-based regressor suitable for streaming data.
- KNNRegressor: A k-nearest neighbors regressor.
Pipelines
Each pipeline uses the same data and preprocessing steps but a different regression algorithm:
- linearRegPipeline: Uses
LinearRegression. - hoeffTreePipeline: Uses
HoeffdingAdaptiveTreeRegressor. - knnRegPipeline: Uses
KNNRegressor.
Each pipeline outputs predictions to its own topic and evaluates performance using three metrics:
- MAE (Mean Absolute Error)
- MSE (Mean Squared Error)
- R2 (R-squared Score)
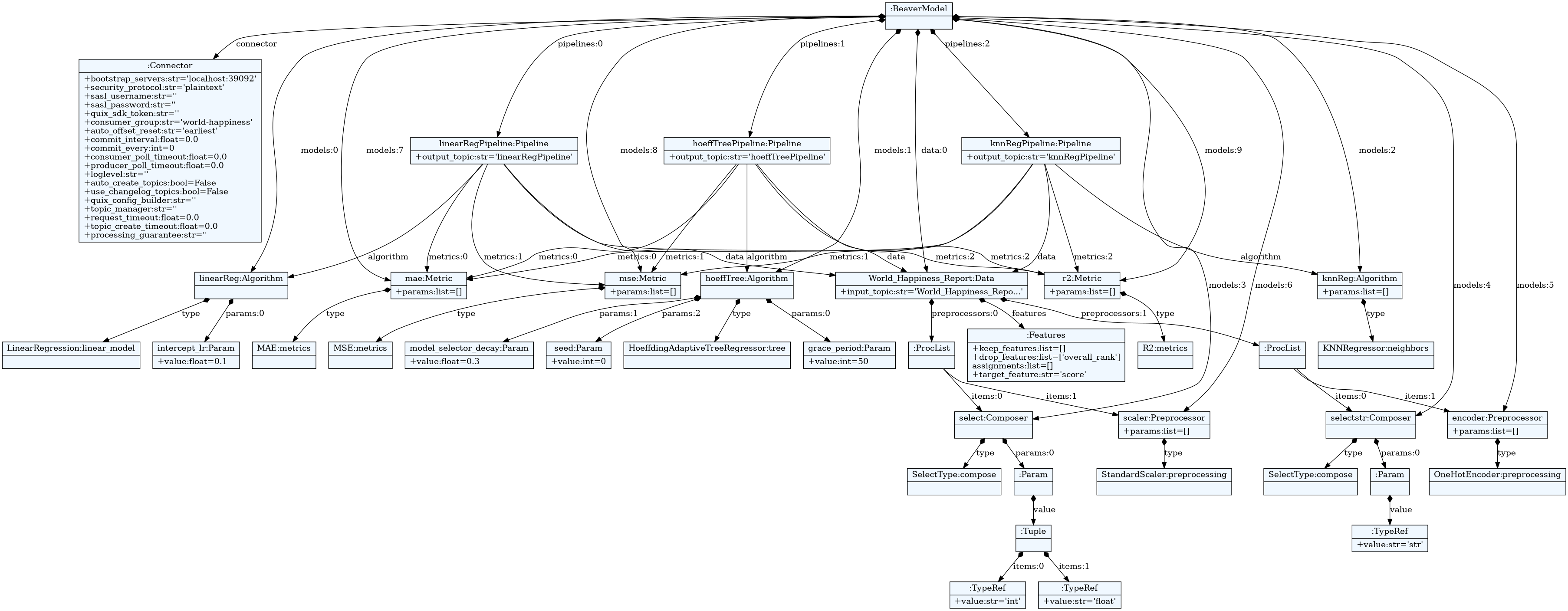
Beaver File Structure
Connector
We start by defining the connector, specifying the Kafka bootstrap servers and security protocol.
connector {
bootstrap_servers = "localhost:39092"
security_protocol = "plaintext"
consumer_group = 'world-happiness'
auto_offset_reset = "earliest"
}
Models
We define the regression algorithms:
algorithm <LinearRegression> linearReg
params:
intercept_lr=0.1
algorithm <HoeffdingAdaptiveTreeRegressor> hoeffTree
params:
grace_period=50,
model_selector_decay=0.3,
seed=0
algorithm <KNNRegressor> knnReg
Feature Selection and Preprocessing
We select numeric and string features separately and apply the appropriate preprocessors:
composer <SelectType> select
params:
(int , float)
composer <SelectType> selectstr
params:
str
preprocessor <OneHotEncoder> encoder
preprocessor <StandardScaler> scaler
Metrics
We define the evaluation metrics:
metric <MAE> mae
metric <MSE> mse
metric <R2> r2
Data
We define the data source, drop the overall_rank feature, and specify the target and preprocessors:
data World_Happiness_Report {
input_topic = "World_Happiness_Report"
features:
drop_features = overall_rank
target_feature = score
preprocessors = select | scaler + selectstr | encoder
}
Pipelines
We define three pipelines, each using a different regression algorithm:
pipeline linearRegPipeline {
output_topic = 'linearRegPipeline'
data = World_Happiness_Report
algorithm = linearReg
metrics = mae , mse , r2
}
pipeline hoeffTreePipeline {
output_topic = 'hoeffTreePipeline'
data = World_Happiness_Report
algorithm = hoeffTree
metrics = mae , mse , r2
}
pipeline knnRegPipeline {
output_topic = 'knnRegPipeline'
data = World_Happiness_Report
algorithm = knnReg
metrics = mae , mse , r2
}
With this configuration, you can efficiently compare multiple regression approaches on the World Happiness Report dataset and gain insights into which model performs best for predicting happiness scores.
connector {
bootstrap_servers = "localhost:39092"
security_protocol = "plaintext"
consumer_group = 'world-happiness'
auto_offset_reset = "earliest"
}
algorithm <LinearRegression> linearReg
params:
intercept_lr=0.1
algorithm <HoeffdingAdaptiveTreeRegressor> hoeffTree
params:
grace_period=50,
model_selector_decay=0.3,
seed=0
algorithm <KNNRegressor> knnReg
composer <SelectType> select
params:
(int , float)
composer <SelectType> selectstr
params:
str
preprocessor <OneHotEncoder> encoder
preprocessor <StandardScaler> scaler
metric <MAE> mae
metric <MSE> mse
metric <R2> r2
data World_Happiness_Report {
input_topic = "World_Happiness_Report"
features:
drop_features = overall_rank
target_feature = score
preprocessors = select | scaler + selectstr | encoder
}
pipeline linearRegPipeline {
output_topic = 'linearRegPipeline'
data = World_Happiness_Report
algorithm = linearReg
metrics = mae , mse , r2
}
pipeline hoeffTreePipeline {
output_topic = 'hoeffTreePipeline'
data = World_Happiness_Report
algorithm = hoeffTree
metrics = mae , mse , r2
}
pipeline knnRegPipeline {
output_topic = 'knnRegPipeline'
data = World_Happiness_Report
algorithm = knnReg
metrics = mae , mse , r2
}
A complete figure of Beaver Model can be seen below